Authors
Anonymous AuthorsAbstract
We propose U-Singer, the first multi-singer emotional singing voice synthesizer that expresses various levels of emotional intensity. During synthesizing singing voices according to the lyrics, pitch, and duration of the music score, U-Singer reflects singer characteristics and emotional intensity by adding variances in pitch, energy, and phoneme duration according to singer ID and emotional intensity. Representing all attributes by conditional residual embeddings in a single unified embedding space, U-Singer controls mutually correlated style attributes, minimizing interference. Additionally, we apply emotion embedding interpolation and extrapolation techniques that lead the model to learn a linear embedding space and allow the model to express emotional intensity levels not included in the training data. In experiments, U-Singer synthesized high-fidelity singing voices reflecting the singer ID and emotional intensity. The visualization of the unified embedding space exhibits that U-singer estimates the correct variations in pitch and energy highly correlated with the singer ID and emotional intensity level.The architecture of U-Singer
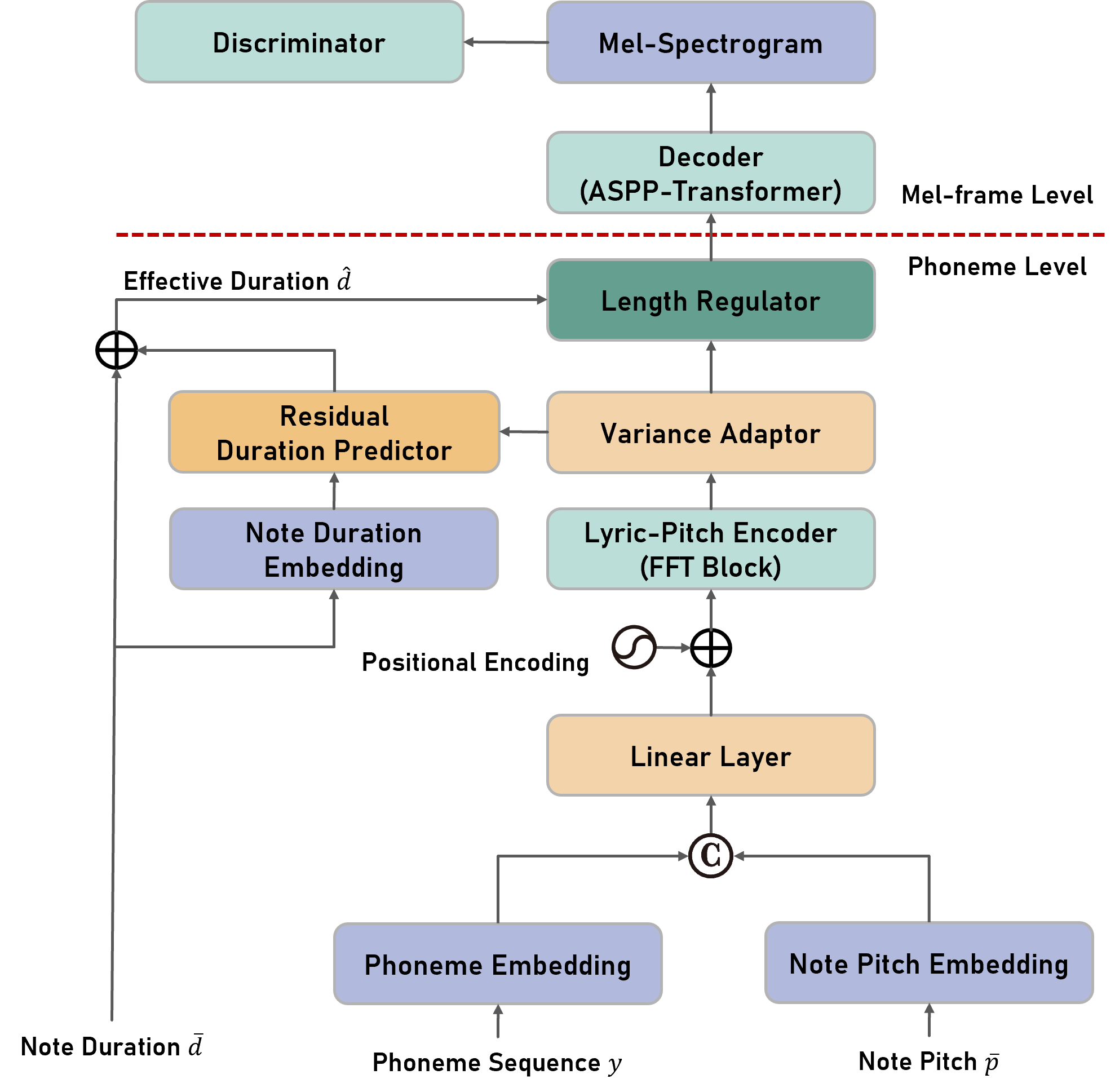
|
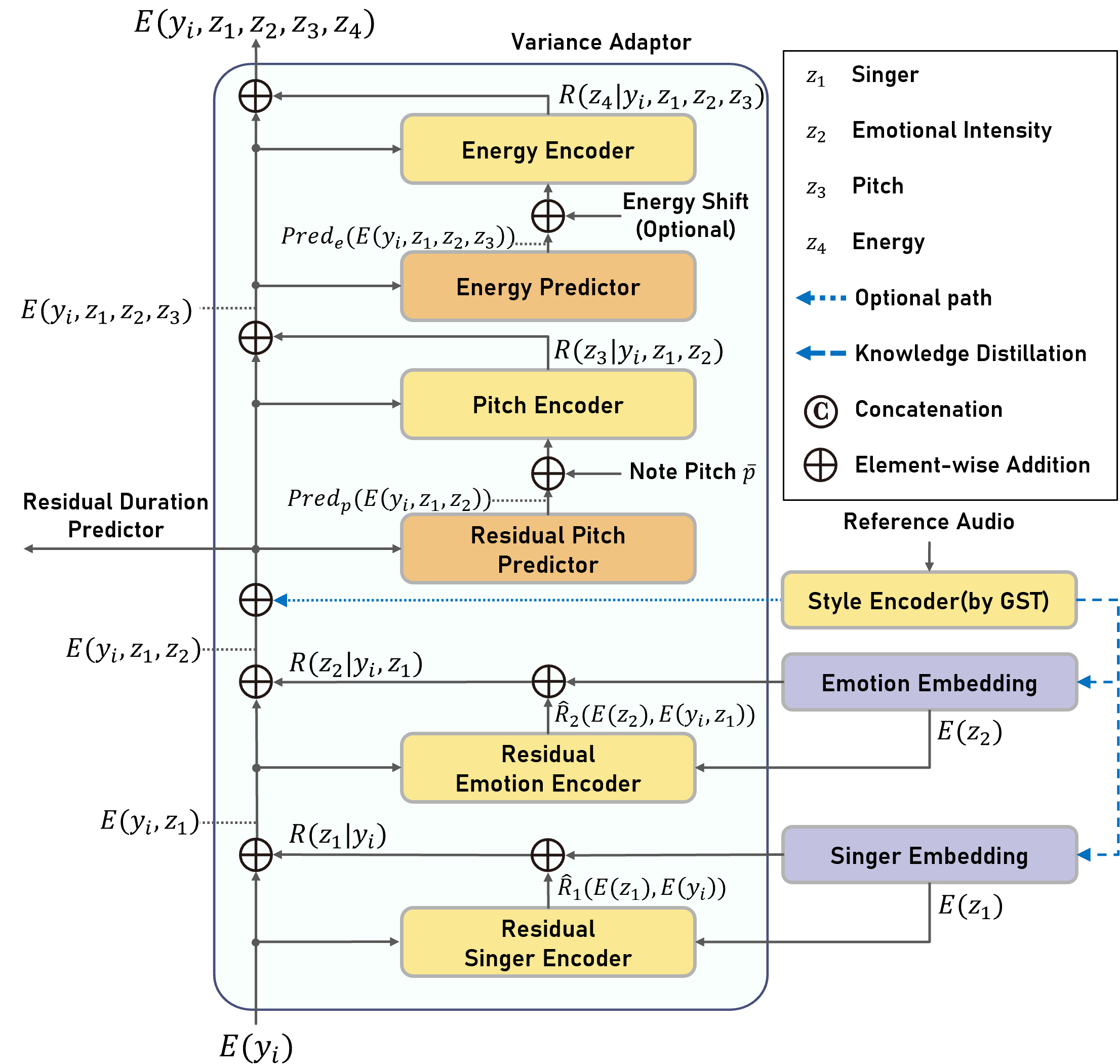
|
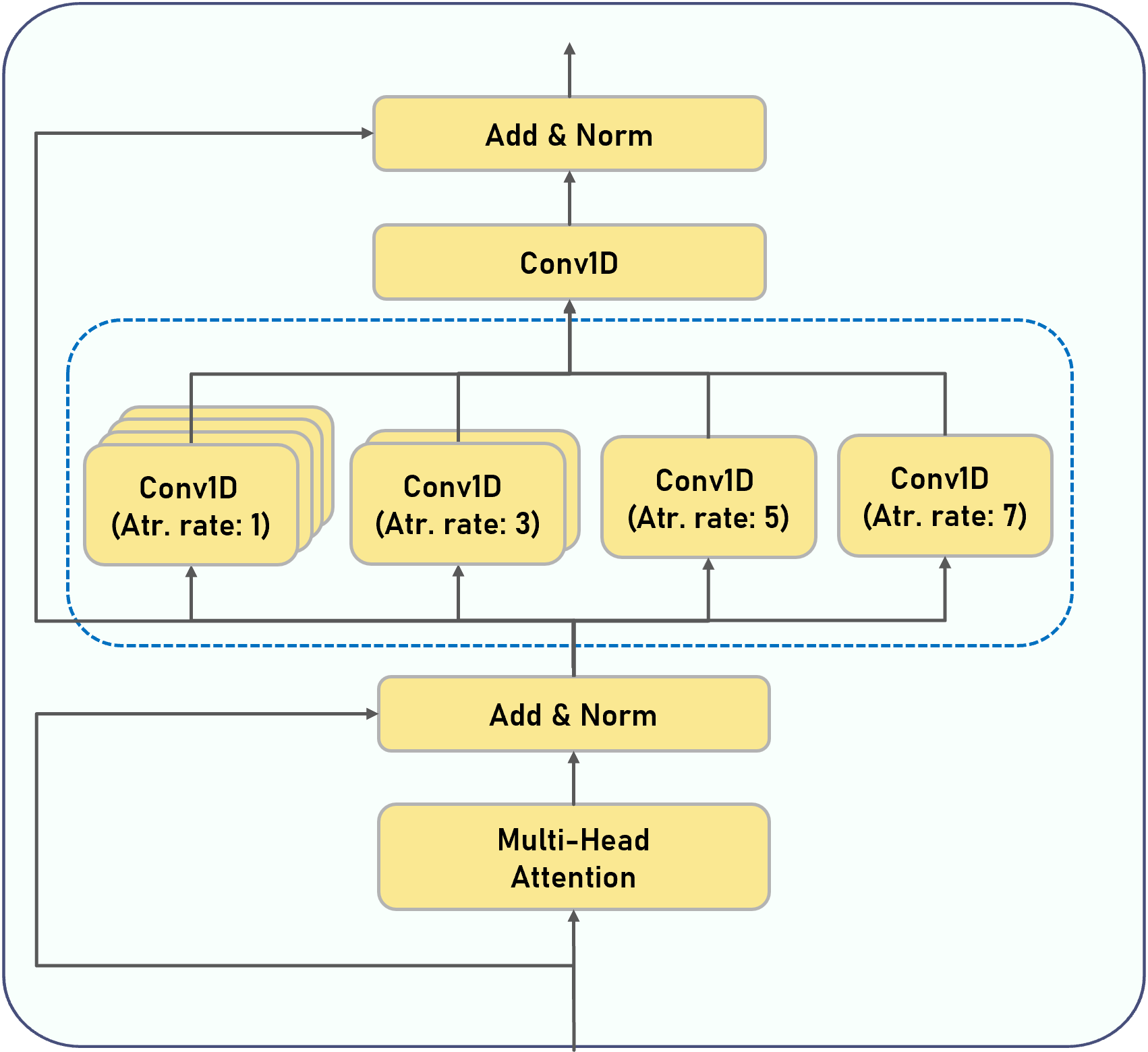
|
|---|---|---|
| (a) Overall Architecture | (b) Variance Adaptor | (c) ASPP-Transformer |
Figure illustrates the structure of U-Singer. It takes lyrics (phoneme sequence), note pitch, and note duration as input. First, it retrieves the low-level embeddings of the phoneme and note pitch from the embedding tables, respectively.
We combine them by concatenation followed by a linear layer. The linear layer provides a more general form and exhibited higher fidelity than element-wise addition in our preliminary experiments.
The lyric-pitch encoder converts the combined embedding into a high-level representation and transmits it to the variance adapter.
Audio Samples
Part 1. Emotion Intensity Control
U-Singer can generate audio samples with different emotional intensities. Here are few samples with emotion of both happy and sad. Furthermore, U-Singer can generate emotional intensity which are not in the dataset.The training data includes emotional intensity levels of 0.3, 0.7, and 1.0. The samples with intensity levels of 0.5 were generated by emotion interpolation, and with intensity levels of 1.3 were generated by emotion extrapolation.
Since we have lots of demo samples, the size of mel-spectrogram is resized in default.
You can easily zoom in the mel-spectrogram images by clicking them and distinguish the differences between generated samples with the change in emotional intensities.
| Female | Neutral | Happy0.3 | Happy0.5(interpolation) | Happy0.7 | Happy1.0 | Happy1.3(extrapolation) |
|---|---|---|---|---|---|---|
| happy sample 1 GT | ||||||
| happy sample 1 mel |  |
 |
 |
 |
 |
 |
| happy sample 1 Syn | ||||||
| happy sample 2 GT | ||||||
| happy sample 2 mel |  |
 |
 |
 |
 |
 |
| happy sample 2 Syn | ||||||
| Female | Neutral | Sad0.3 | Sad0.5(interpolation) | Sad0.7 | Sad1.0 | Sad1.3(extrapolation) |
| sad sample 1 GT | ||||||
| sad sample 1 mel |  |
 |
 |
 |
 |
 |
| sad sample 1 Syn | ||||||
| sad sample 2 GT | ||||||
| sad sample 2 mel |  |
 |
 |
 |
 |
 |
| sad sample 2 Syn | ||||||
| Male | Neutral | Happy0.3 | Happy0.5(interpolation) | Happy0.7 | Happy1.0 | Happy1.3(extrapolation) |
| happy sample 1 GT | ||||||
| happy sample 1 mel |  |
 |
 |
 |
 |
 |
| happy sample 1 Syn | ||||||
| happy sample 2 GT | ||||||
| happy sample 2 mel |  |
 |
 |
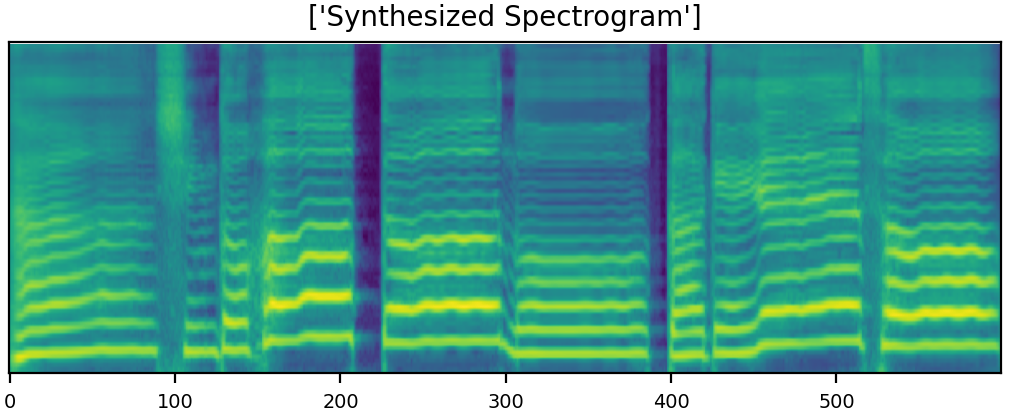 |
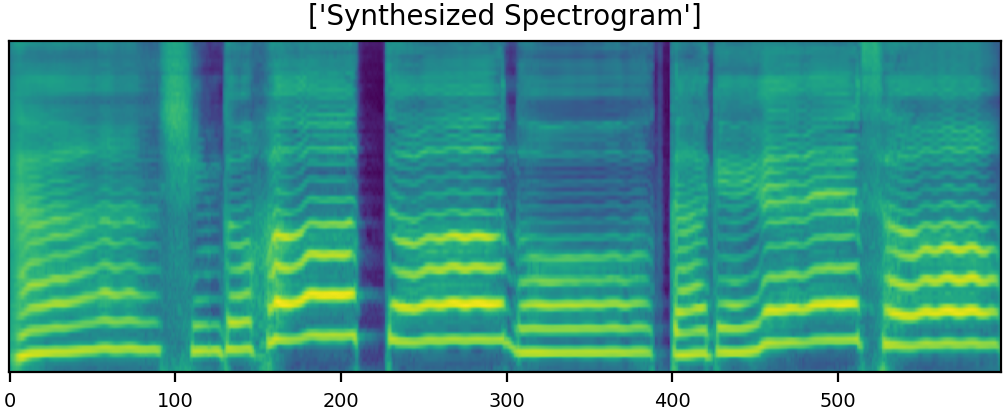 |
 |
| happy sample 2 Syn | ||||||
| Male | Neutral | Sad0.3 | Sad0.5(interpolation) | Sad0.7 | Sad1.0 | Sad1.3(extrapolation) |
| sad sample 1 GT | ||||||
| sad sample 1 mel | 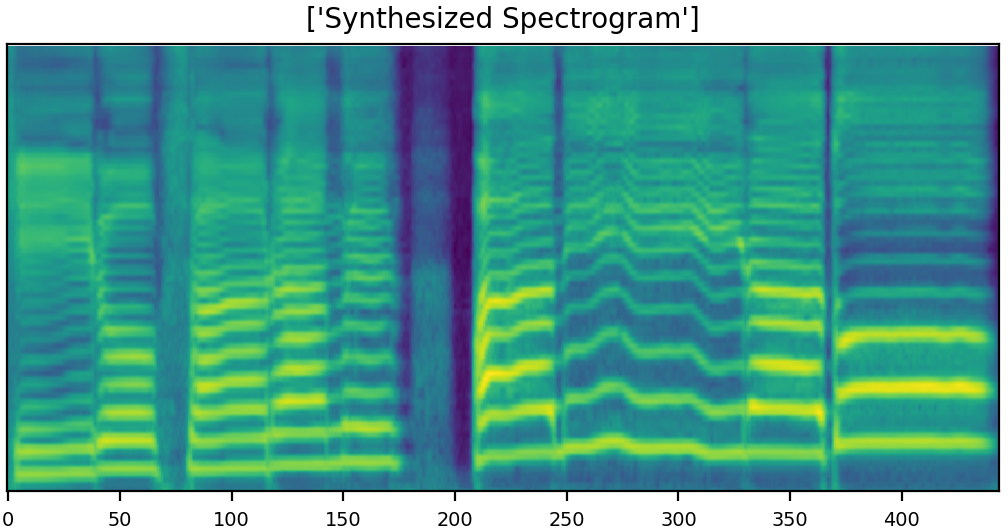 |
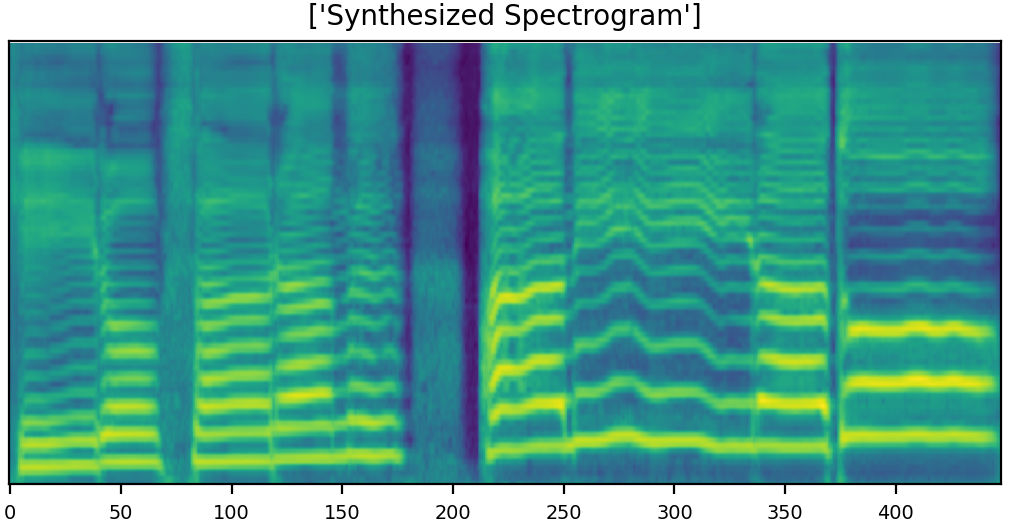 |
 |
 |
 |
 |
| sad sample 1 Syn | ||||||
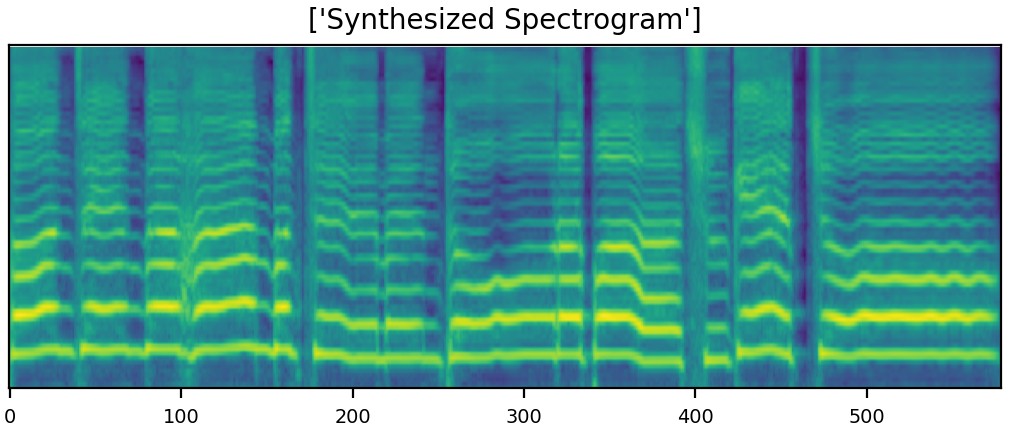
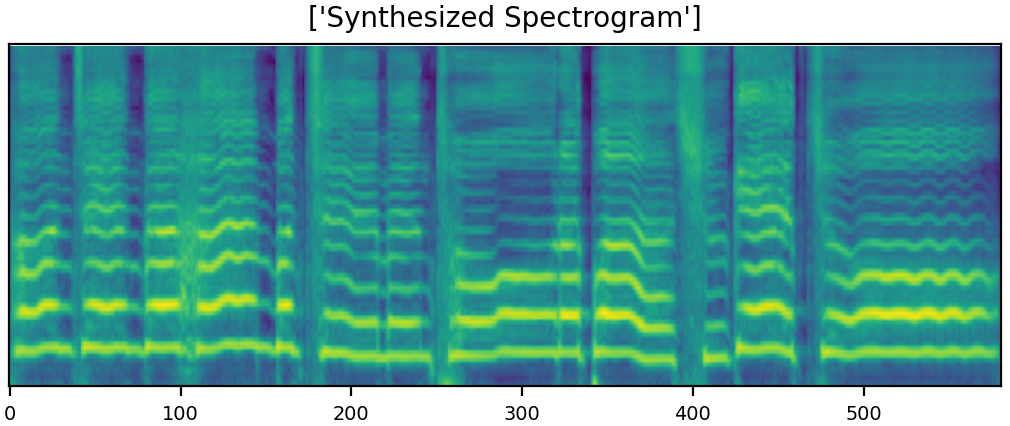
| sad sample 2 GT | ||||||
| sad sample 2 mel |  |
 |
 |
 |
 |
 |
| sad sample 2 Syn |
Part 2. Cross-Emotional Synthesis
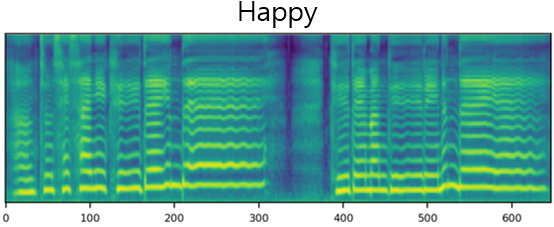
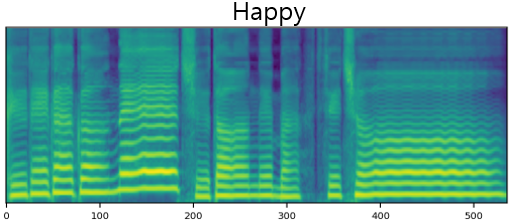
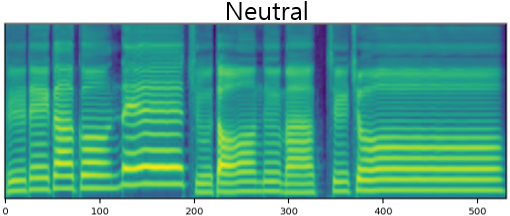
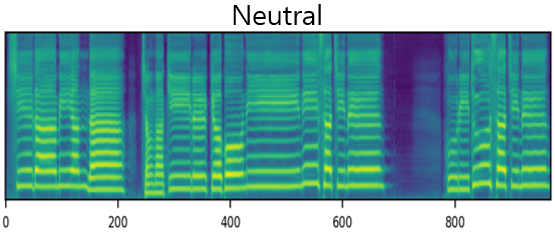
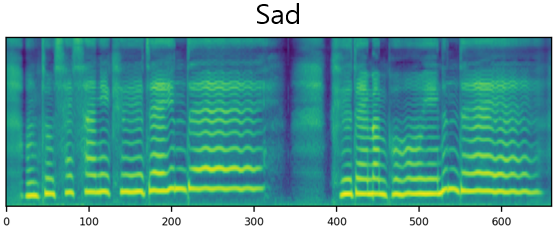
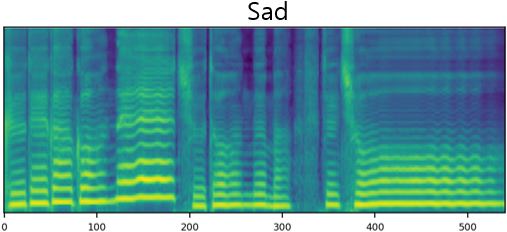
The result of synthesizing happy and sad songs in happy, neutral, and sad voices, respectively.U-Singer can synthesize happy songs in sad voices and sad songs in happy voices.
| Happy Song(Female) | Sad Song(Female) | Happy Song(Male) | Sad Song(Male) | |
|---|---|---|---|---|
| Mel-Spectrogram | 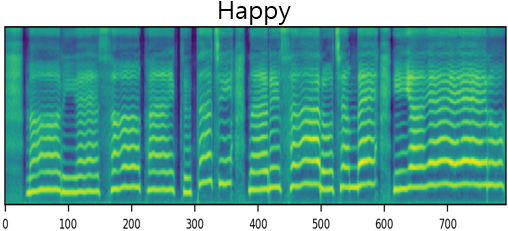 |
 |
 |
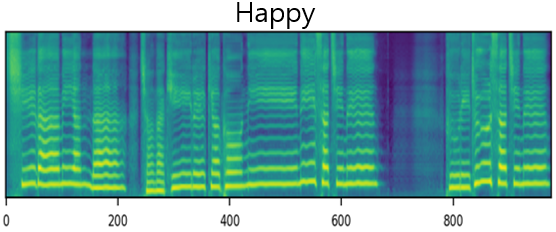 |
| Happy | ||||
| Mel-Spectrogram | 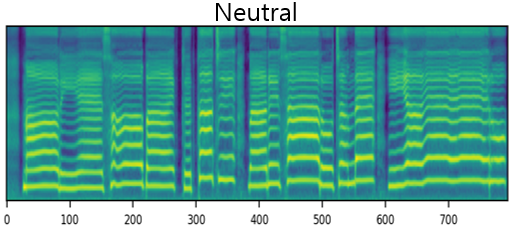 |
 |
 |
 |
| Neutral | ||||
| Mel-Spectrogram | 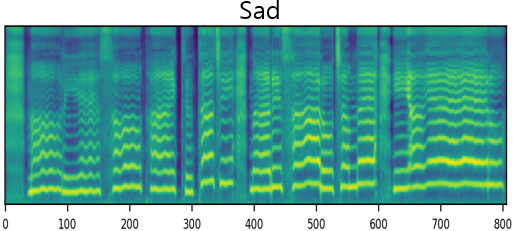 |
 |
 |
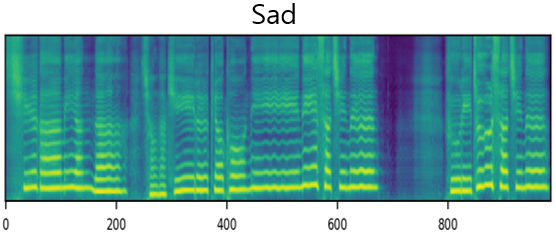 |
| Sad |
Part 3. Singer ID Control
U-Singer can generate audio samples containing distinguishable singer characteristic. We trained model with 5 different singer, including Singer from CSD dataset which not contains emotion information(about 2.12 hours long).Other four singers consist of Professional female singer(about 0.57 hours long), Professional male singer(about 0.52 hours long), Amateur female singer(about 6.01 hours long), Amateur male singer(about 5.22 hours long).
We trained 13.49 hours(1.99 hours of CSD dataset, 11.5 hours of collected dataset) in total.
| Amateur Female | Amateur Male | CSD Female | Professional Female(small amount data) | Professional Male(small amount data) | |
|---|---|---|---|---|---|
| Sample 1 wav | |||||
| Sample 2 wav | |||||
| Sample 3 wav | |||||
| Sample 4 wav |
Visualization of Style Attributes in Unified Embedding Space
Part 1. Singer and Emotion Embeddings
 |
 |
|---|---|
| (a) Singer Embeddings | (b) Emotion Embeddings |
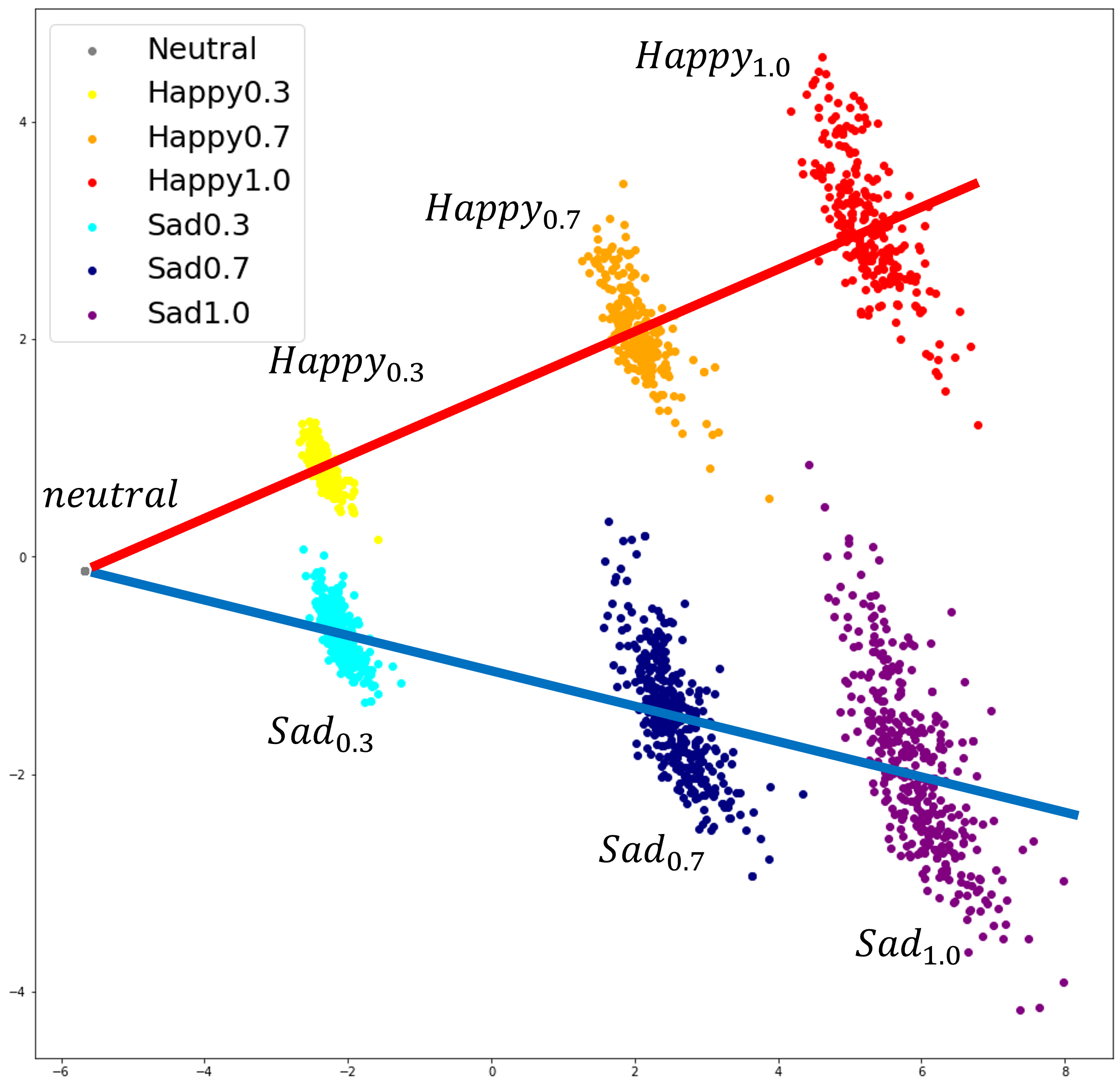
Visualization of U-Singer's residual embeddings. We visualized Residual embeddings of singer and emotion into 2-dimensional space using principle component analysis (PCA). (The red and blue lines in the Figure b were manually drawn for the convenience of the reader.)
(F0: CSD Singer, F1: Professional Female Singer, M1: Professional Male Singer, F2: Amateur Female Singer, M2: Amateur Male Singer)
Part 2. Pitch and Energy Embeddings
1. Pitch embeddings
 |
 |
 |
|
|---|---|---|---|
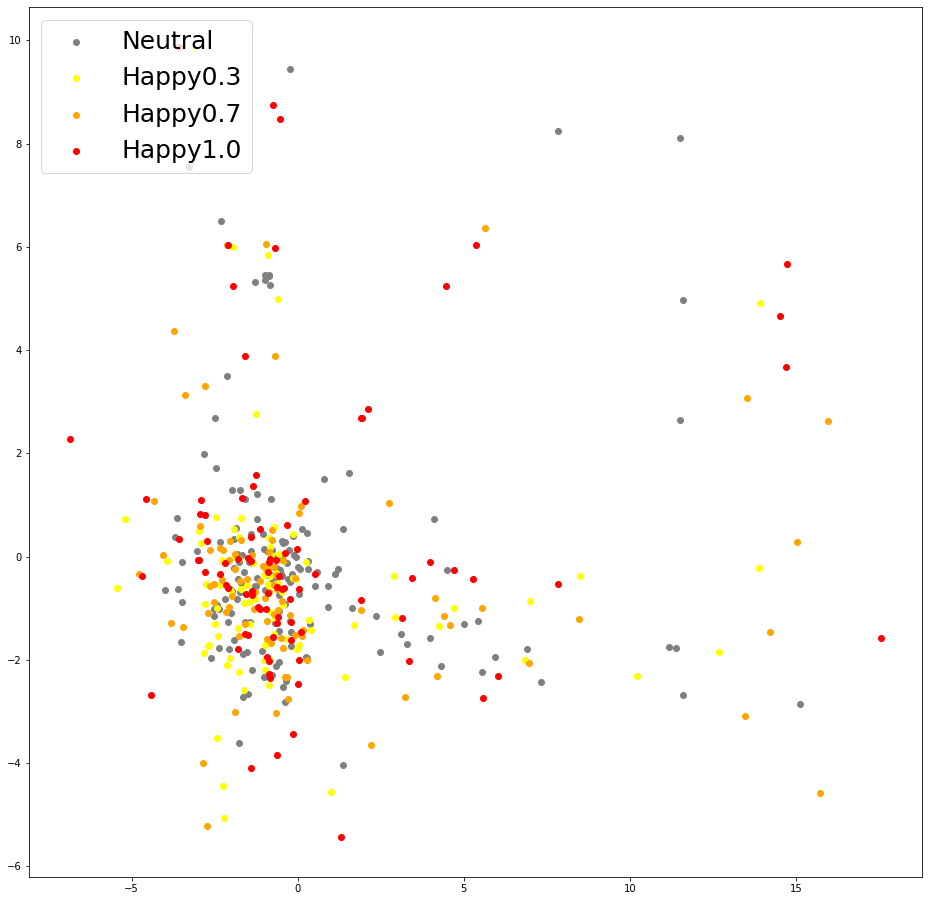
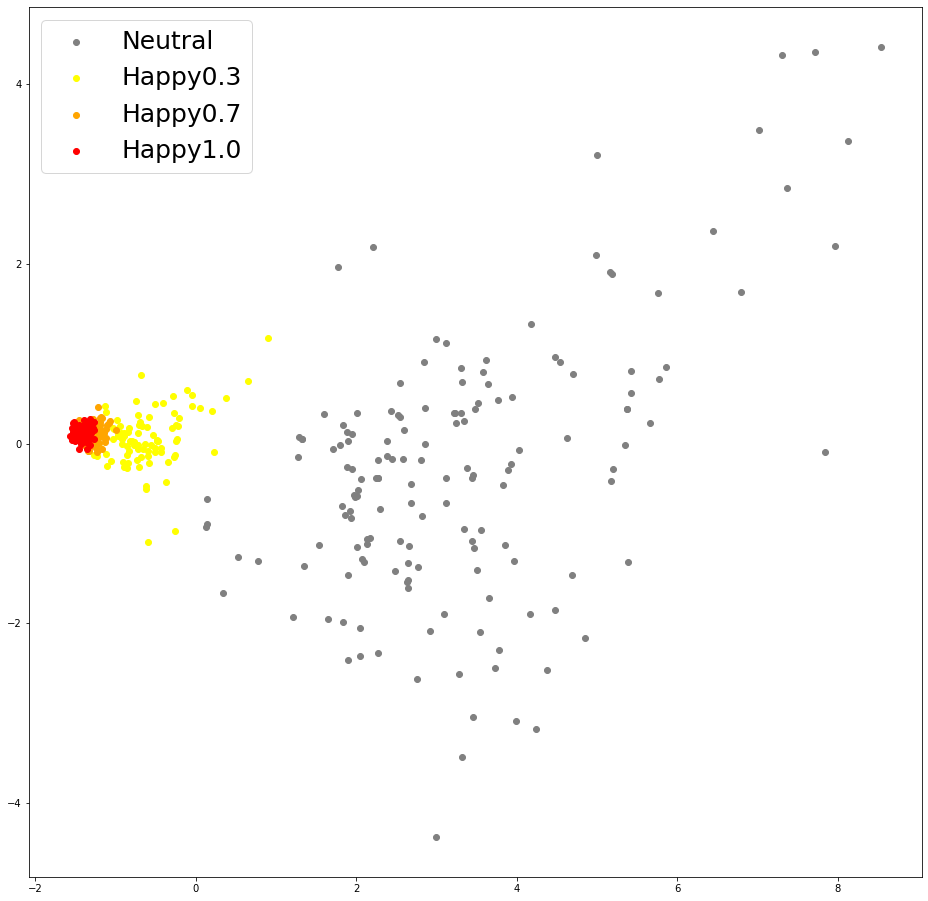
| (a) Pitch Embeddings of baseline (Happy) | (b) Pitch Embeddings of baseline (Sad) | (c) Pitch Embeddings of U-Singer (Happy) | (d) Pitch Embeddings of U-Singer (Sad) |
Visualization of pitch embeddings obtained by conventional encoder of EXT.FS2(Figure a and b) and residual encoder of U-Singer(Figure c and d). The correlation between pitch embedding and emotional intensity is evident in (c) and (d), but not in (a) and (b).
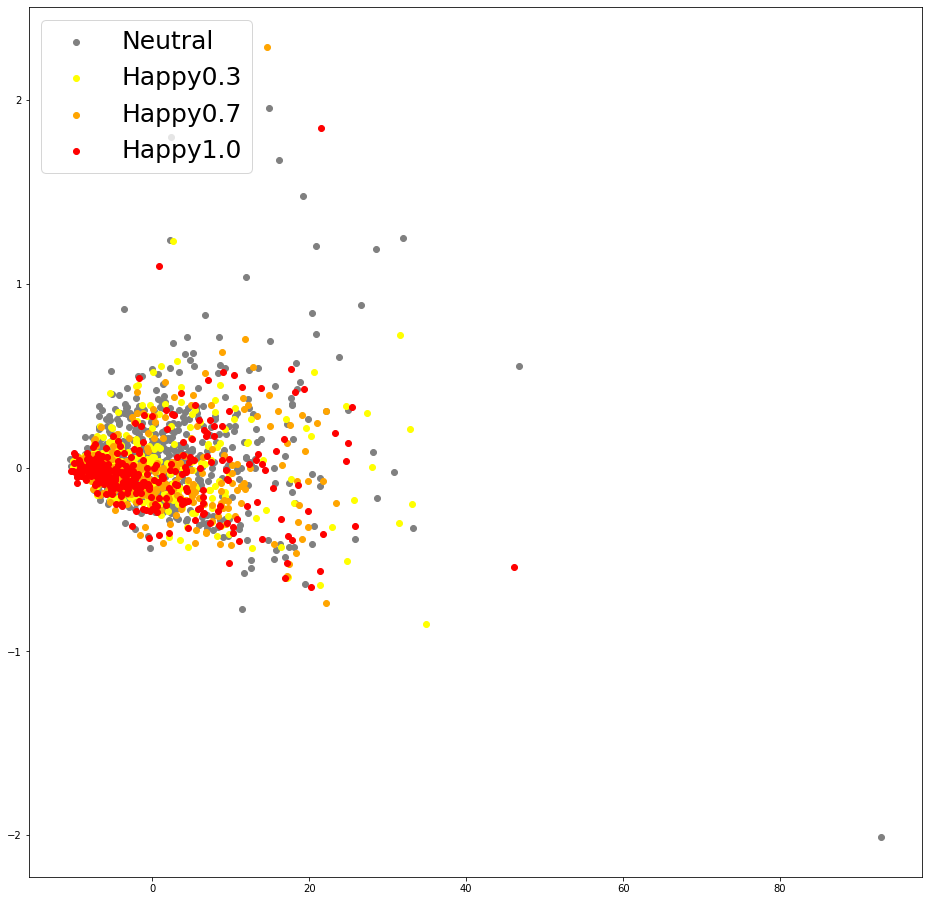
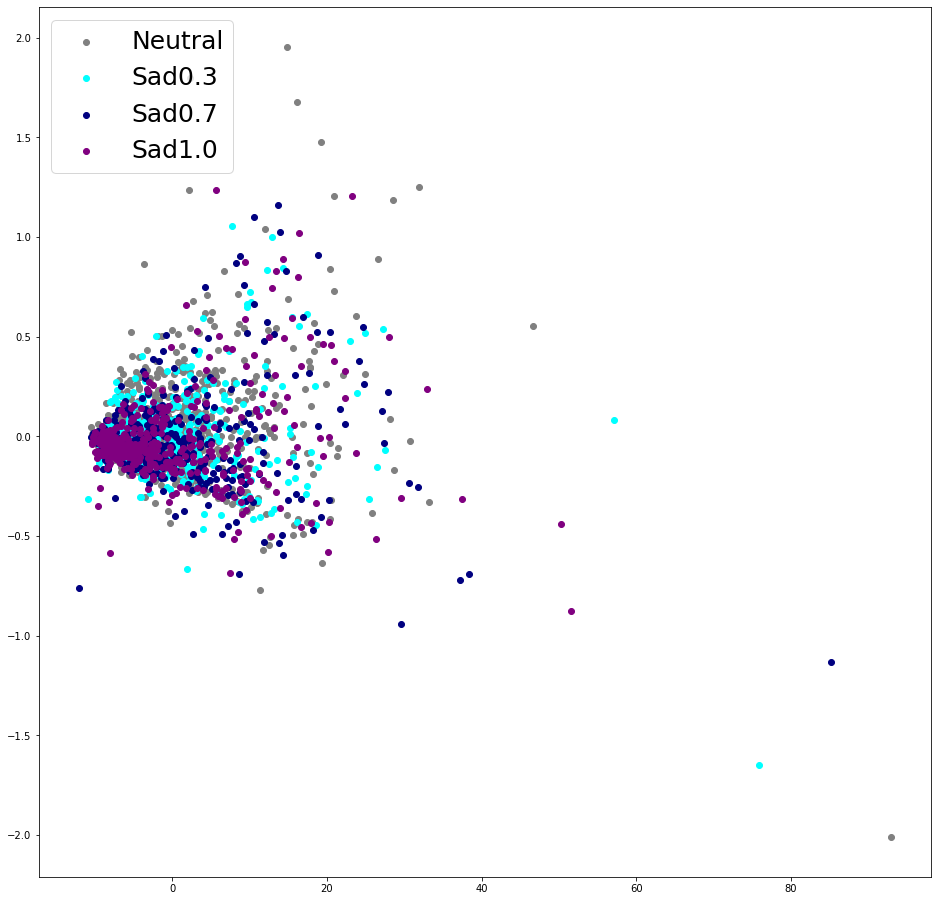
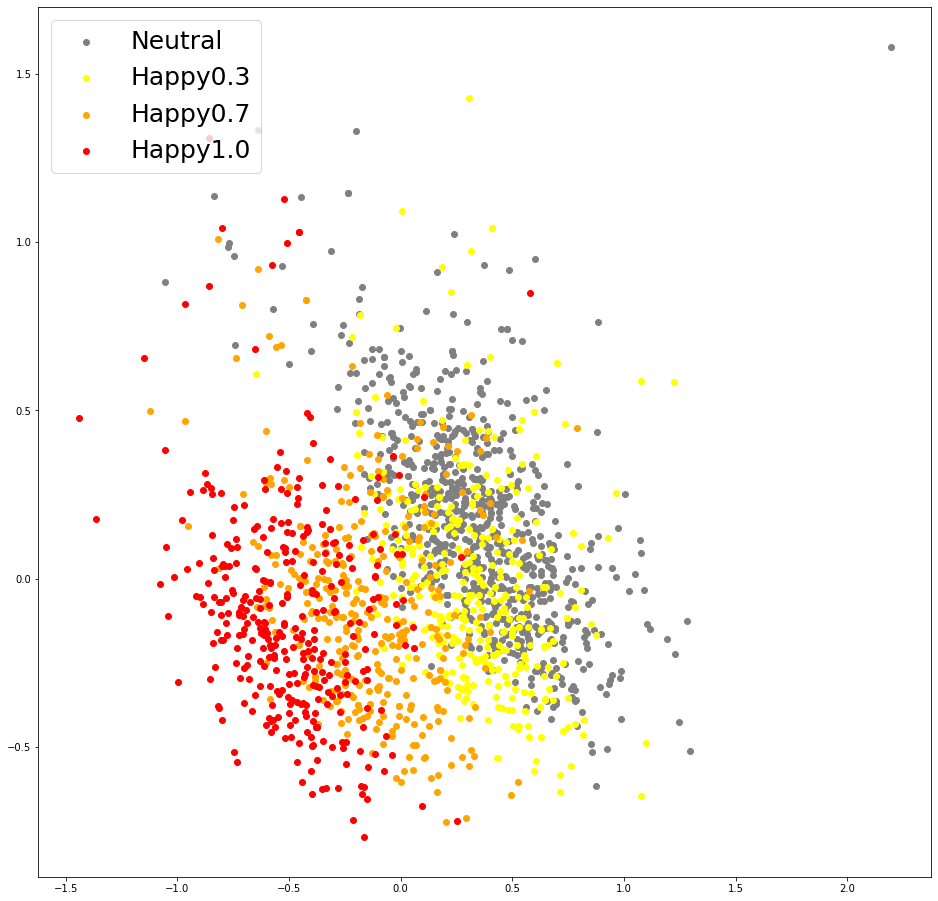
2. Energy embeddings
 |
 |
 |
|
|---|---|---|---|
| (a) Energy Embeddings of baseline (Happy) | (b) Energy Embeddings of baseline (Sad) | (c) Energy Embeddings of U-Singer (Happy) | (d) Energy Embeddings of U-Singer (Sad) |
Visualization of energy embeddings obtained by conventional encoder of EXT.FS2(Figure a and b) and residual encoder of U-Singer(Figure c and d). The correlation between energy embedding and emotional intensity is evident in (c) and (d), but not in (a) and (b).
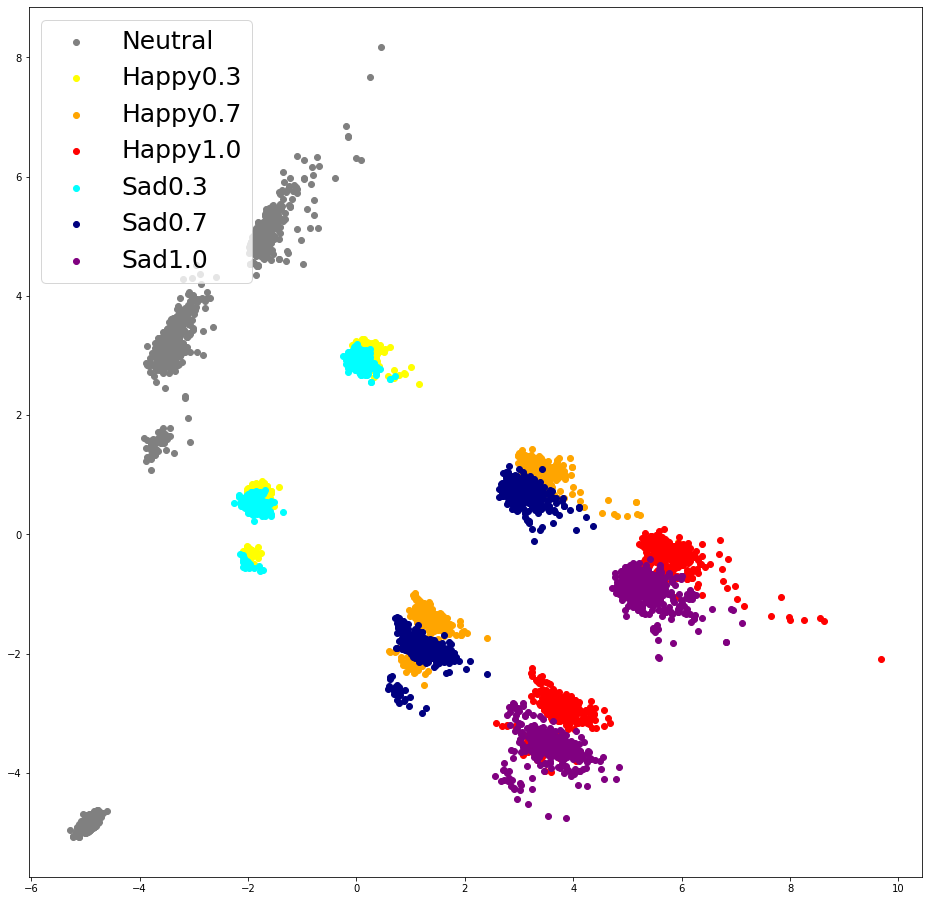
Part 3. Full style embeddings
 |
 |
|---|---|
| (a) Full style embeddings colored by singer | (b) Full style embeddings coloered by emotional intensities |
Visualization of U-Singer's full style embeddings